How does a search engine work ?
It is a daily gesture to carry out a search on the web. You enter a request, or dictate it to your smartphone, and you get an optimal response. But how do search engines work? What exactly is a search engine? What are its mechanisms? How does the Google algorithm work and how to use it wisely?
Table of contents
What is a search engine?
Behind our systemic attitude of performing a search, there is a search engine. A search engine is an application used to sort the results, i.e. the pages of websites for a request made. There are many search engines, but today Google is the best known and most used in the world with around 92% market share (Russia mainly uses Yandex and China only uses Baidu).
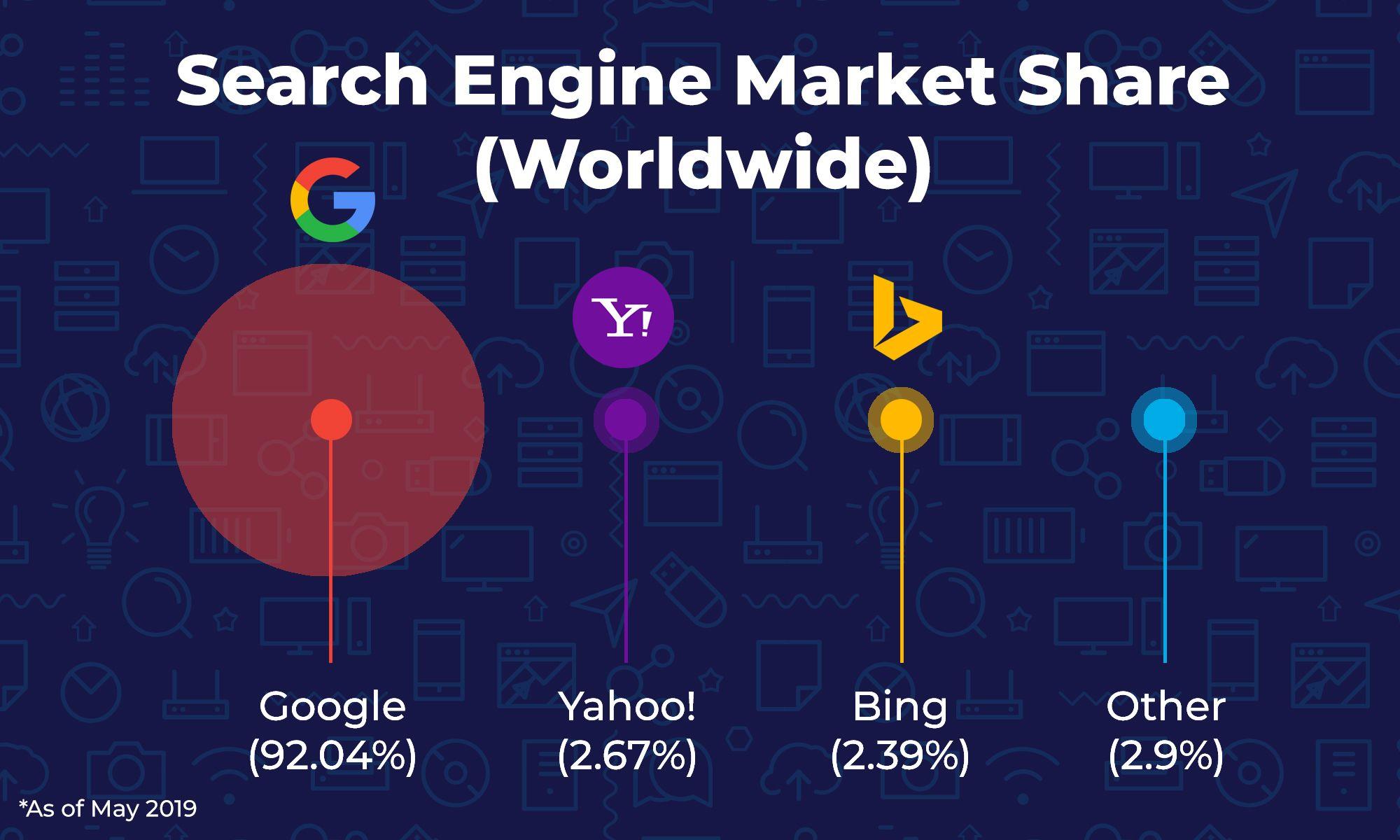
World search engine market share (via RiseUp Strategies)
Google, a search engine like any other?
If Google is the most popular, it is because it is the most optimized: it includes many algorithms, with daily updates capable of crawling sites (almost) indefinitely. Finally, the latter is also the most UX friendly with the regular introduction of new featured snippets and features that make browsing easier and more enjoyable (like People Also Asked for example).
Search Engines, Not So Common Search Engines
Basically, a search engine is a mechanism for indexing web pages. Its purpose is to offer the most relevant results according to a given query. To present these results to the user, the machine uses robots called crawlers, which analyze the content and presentation of a web page. Depending on the results obtained, they assign them a score which will be used to classify them when presenting them to the user. When the user enters a query in the search bar, the machine offers him the results that it has analyzed as the most relevant in descending order.
What are the mechanisms of a search engine?
The process a search engine follows to select pages to index involves several steps: first, crawling, then indexing and updates.
What is the crawling or exploration phase?
When designing a website, it's important to create a sitemap (much like an architect building a house). This plan, which is called the sitemap, is not necessarily used to organize the order of the pages of its website upstream, but above all to present each of the pages to Google. It then specifies the pages to be analyzed with a view to indexing the site on the search engine. Google then sends its Googlebot, a crawler, which navigates among the pages of the site to assess the quality of their content (a bit like a teacher who corrects copies). Once the exploration is complete, Google will assign a positioning of the page on certain queries, as a notation, since it is the purpose of a page to be browsed by users. This is called SEO.
How often does Google crawl a website?
The exploration, or crawling, is carried out periodically, according to the updating of the website. Thus, if the content is modified: enhanced or enriched, the robot re-evaluates its position and brings it up among the search results. On the contrary, if a site is not regularly updated (if new pages are not added or if its content is not enriched), then it risks losing places over time. The frequency of the different crawlings depends on the crawl budget allocated to the website.
What is the crawl budget?
The crawl budget, or crawl budget, or indexing budget corresponds to the maximum number of pages that the GoogleBot will crawl at once. In practice, a site with a very large number of pages (like an e-commerce for example) has a higher crawl budget than a smaller site (like a blog or a showcase site). The GoogleBot crawls the pages very frequently in order to know where to position the site among the search results for a given query. The crawler is like an inspector who comes to check the content, but also the technical performance of the website. In principle, the larger the crawl budget, the more likely the site is to be correctly referenced if the designer implements the necessary means. It is also important to facilitate the navigation of robots by respecting a few principles, such as:
- setting up internal networking,
- offering titles of different levels,
- repairing broken links,
- etc.
What is the search engine indexing phase?
The indexing phase is simply the fact that a search engine positions websites according to the results observed during the exploration phase. At the end of the crawling, the search engine classifies the websites according to a specific algorithm which combines, among other things, the following main information:
- relevance of the information given to a specific problem,
- originality of the content,
- ease of navigation on the page ( UX),
- technical performance of the site (loading speed, structured data, etc.).
According to the evaluation assigned to each of these criteria, the algorithm decides on a placement of the site for a given request. This is the very strategy of natural referencing. Each search engine has its own algorithm, developed internally, to classify sites according to its own functioning.
How does the Google algorithm work?
The most famous algorithm is unsurprisingly that of the Google search engine. However, it also includes many intricacies that many web designers seek to unravel.
We know that the algorithm takes into account the various criteria raised, and that it penalizes black hat, which correspond to a kind of “SEO fraud” and attempt to trap it. The algorithm is the search engine's constant subject of reflection and evolves twice a day with a major update once or twice a year. For example, the Penguin filter, an updated version of the algorithm, launched in 2012, penalizes sites that have sought to acquire external links (backlinks) in a fraudulent manner: a designer buys links redirecting to his website from other sites that have nothing to do with his problem in order to usurp authority.
Overall, Google indicates what the new updates to its algorithm consist of but does not reveal the secrets of its mechanisms, in order to be able to maintain control over the web. If the precise rules of the functioning of the algorithm were revealed then the websites would all become irreproachable and the very principle of the search engine would be cheated.
The Google algorithm, an exemplary case of Machine Learning
The Google algorithm is constantly evolving, and it has been worked on so much that it is able to understand the intention of the user and also the logic of an argument or the user journey on one page. Here is a concrete example: a famous SEO software tells a web editor that the term “best baby milk” attracts 720 monthly searches.
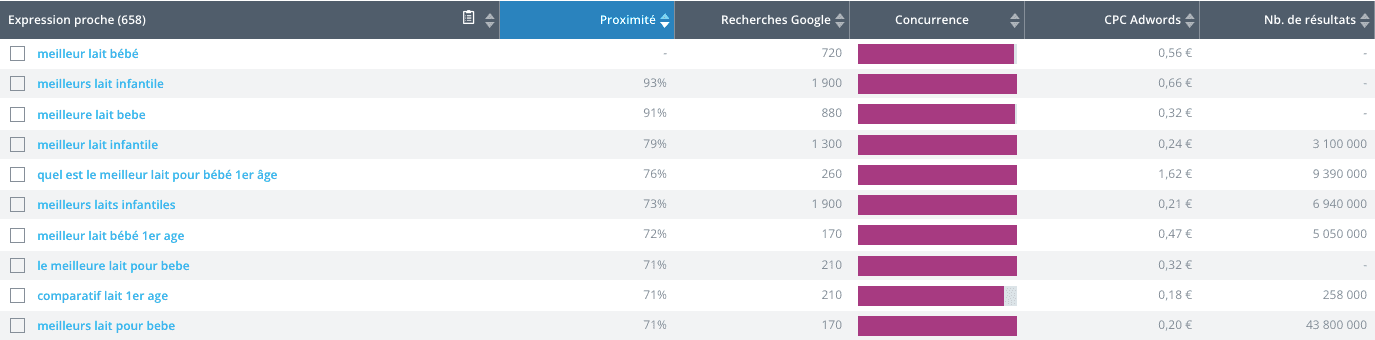
Indeed, the user looking for information enters this query in the search bar. On the other hand, the editor, who writes an article on this query, cannot enter these exact terms, since it is not linguistically correct. The page named “What is the best baby milk?” will nevertheless fall in the search results for the query “best baby milk” since Google detects the intention of the search and associates it with the theme of the page. It can even associate content whose names completely diverge from the search terms if it detects a certain relevance between the information given and the query entered. As evidenced by the example below, the first search result for the query “best baby milk” is a page whose title is “Best 1st age milk in 2021 (baby from 0 to 6 months)”.
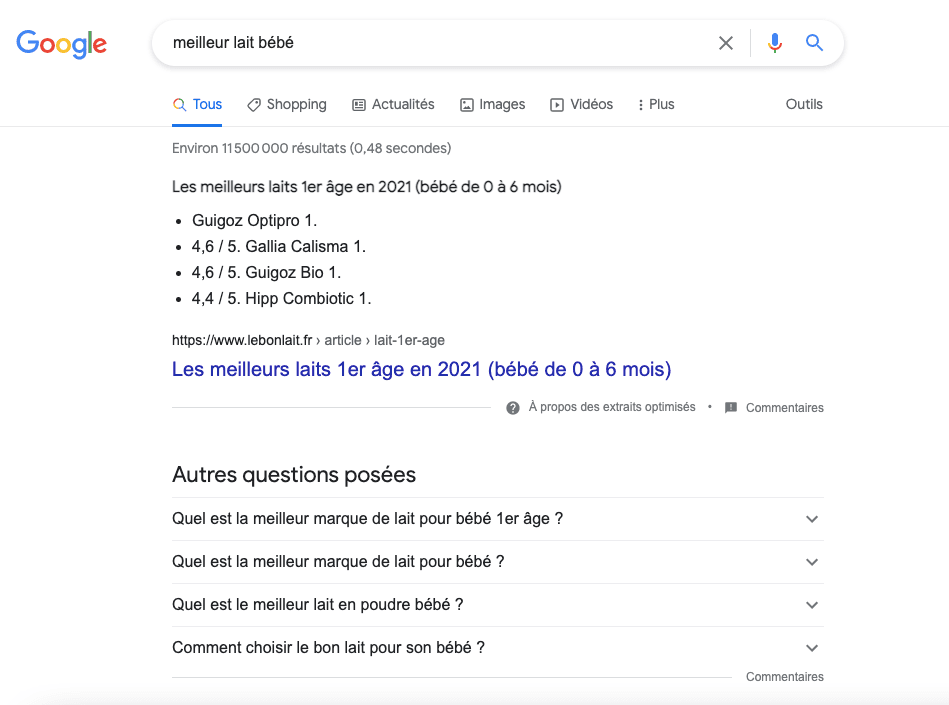
The Google algorithm is thus an artificial intelligence based on machine learning, capable of making its own choices and detecting the linguistic and logical paths taken by users.
Google Penalties and Manual Actions
The algorithm is not the only operational agent in the game of website indexing. There are also Google agents who examine a website after an automated detection or after a denunciation of practices contrary to Google's principles. These actions are not automated but do depend on the passage of human agents, which is why they are called manual actions. They are often the cause of a drop in traffic and can be spotted via the Google Search Console. Following a manual penalty, it is possible to correct errors and request a new examination in order to lift the latter.
How do I ensure that the algorithm favors my natural referencing?
For the search engine to position a website at the top of its search results, we apply the principles of natural referencing or SEO (Search Engine Optimization). SEO is a technical science that evaluates the various criteria of optimal referencing of a site and implements modifications in order to enhance the latter in the eyes of the algorithm. To be clear, SEO is not intended to fool the search engine, but to satisfy its demands in order to optimize the qualities of a site. Thus, concretely, the goal of SEO is to make a website relevant, filled with information and original content and to fully adapt it to the needs of users from a navigational point of view.
Web writing
Web writing is a very important part of SEO, aiming to optimize the editorial and editorial content of a website in order to satisfy search engines. If before, SEO consisted mainly of placing many keywords related to a query within a text, this activity has evolved, like the Google algorithm.
Web writing now aims for:
- editorial quality (short and concise sentences)
- originality (its uniqueness, by prohibiting copy/paste)
- information richness (internal mesh and external links)
- structural hierarchy (implementation of titles and -titles)
of a content.
UX Design
The UX of a page on a website concerns its navigational ergonomics: is it easy to navigate the page and find the information you are looking for? The SEO thus includes a whole section dedicated to the aesthetics and the comfort of reading the page. We adopt several distinct techniques to optimize the UX, but among them in particular:
- the insertion of media (illustrations, videos, computer graphics),
- the provision of CTA buttons (call to action, which serve an action highlighted on the site “learn more”, “contact us”...),
- the work of colorimetry to highlight certain points,
- the layout of content at a specific location on the page.
Loading time optimization
200 milliseconds, or 2 seconds: this is the maximum loading time allocated to a web page. The server, the technical constraints of the site, but also its content, determine the loading time of a page. You must constantly check the latency time of the pages of a site in order to reduce the media or if possible refactor the pages that are too heavy to load. It is better to do without a content page than to see it slow down the performance of the site.
Authority
Finally, the authority of a site is also the goal of many web workers. The goal: show Google's credentials and promote the expertise and seriousness of a site. The method: acquire backlinks from other sites, develop your expertise with other media (books, television, radio, podcasts, etc.)...
