Comment fonctionne un moteur de recherche ?
C’est un geste quotidien que d’effectuer une recherche sur le web. On saisit une requête, ou on la dicte à son smartphone, et on obtient une réponse optimale. Mais comment fonctionnent les moteurs de recherche ? Qu’est-ce, au juste, qu’un moteur de recherche ? Quels sont ses mécanismes ? Comment fonctionne l’algorithme Google et comment l’utiliser à bon escient ?
Sommaire
- Qu’est-ce qu’un moteur de recherche ?
- Quels sont les mécanismes d’un moteur de recherche ?
- Comment faire en sorte que l'algorithme favorise mon référencement naturel ?
Qu’est-ce qu’un moteur de recherche ?
Derrière notre attitude systémique consistant à effectuer une recherche, il y a un moteur de recherche. Un moteur de recherche est une application servant à trier les résultats, soit les pages des sites internet pour une requête effectuée. Il existe de très nombreux moteurs de recherche, mais aujourd’hui Google est le plus connu et le plus utilisé au monde avec environ 92% de parts de marché (la Russie utilise principalement Yandex et la Chine utilise uniquement Baidu).
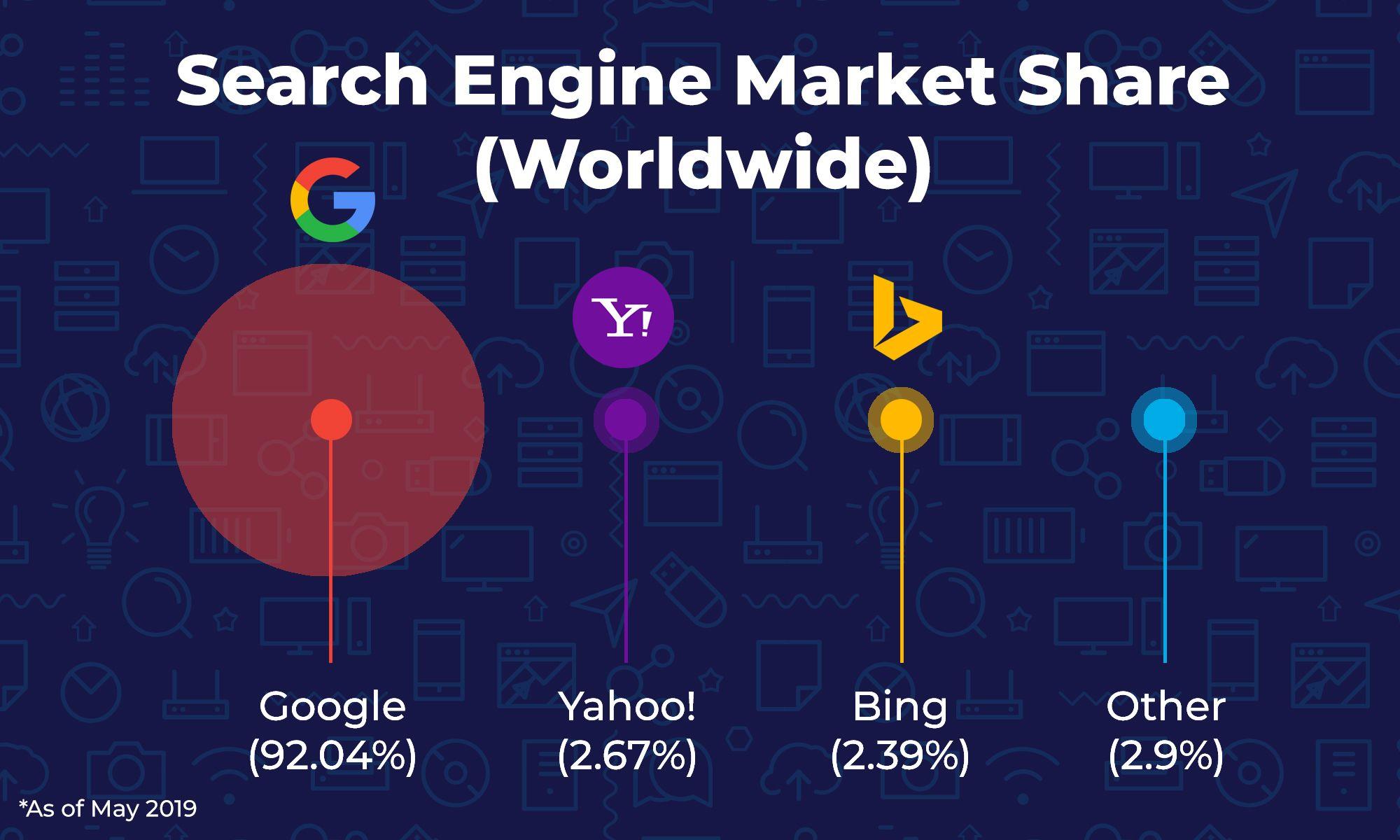
Parts de marché des moteurs de recherche dans le monde (via RiseUp Strategies)
Google, un moteur de recherche comme les autres ?
Si Google est le plus populaire, c’est parce qu’il est le plus optimisé : il comprend des algorithmes nombreux, avec des mises à jour quotidiennes capables de crawler les sites (presque) indéfiniment. Enfin, ce dernier est également le plus UX friendly avec la mise en place régulière de nouveaux featured snippets et de fonctionnalités qui rendent la navigation plus simple et agréable (comme les People Also Asked par exemple).
Les moteurs de recherche, des Search Engines pas si communs
Grossièrement, un moteur de recherche est un mécanisme d’indexation de pages web. Son but est de proposer les résultats les plus pertinents selon une requête donnée. Pour présenter ces résultats à l’utilisateur, la machine utilise des robots que l’on appelle crawlers, qui analysent le contenu et la présentation d’une page web. En fonction des résultats obtenus, ils leur attribuent un scoring qui leur servira à les classifier au moment de les présenter à l’utilisateur. Lorsque l’utilisateur saisit une requête dans la barre de recherche, la machine lui propose les résultats qu’elle a analysés comme les plus pertinents dans l’ordre décroissant.
Quels sont les mécanismes d’un moteur de recherche ?
Le processus que suit un moteur de recherche pour sélectionner les pages à indexer comporte plusieurs étapes : tout d’abord, le crawling, puis l’indexation et les mises à jour.
Qu’est-ce-que la phase de crawling, ou d’exploration ?
Lorsque l’on conçoit un site web, il est important de créer un plan du site (un peu comme un architecte qui construit une maison). Ce plan, que l’on appelle le sitemap, ne sert pas forcément à organiser l’ordre des pages de son site web en amont, mais surtout à présenter chacune des pages à Google. On lui précise alors les pages à analyser en vue de l’indexation du site sur le moteur de recherche. Google envoie alors son Googlebot, un crawler, qui navigue parmi les pages du site pour évaluer la qualité de leur contenu (un peu comme un prof qui corrige des copies). Une fois l’exploration terminée, Google va attribuer un positionnement de la page sur certaines requêtes, en guise de notation, puisque c’est le but d’une page que d’être parcourue par des utilisateurs. C’est ce que l’on appelle le référencement naturel.
A quelle fréquence Google crawle-t-il un site web ?
L’exploration, ou crawling, est réalisée de manière périodique, selon l’actualisation du site web. Ainsi, si le contenu est modifié : valorisé ou enrichi, le robot ré-évalue sa position et le fait remonter parmi les résultats de recherche. Au contraire, si un site n’est pas régulièrement mis à jour (si on n’ajoute pas de nouvelles pages ou si on n’enrichit pas son contenu), alors il risque de perdre des places au fil du temps. La fréquence des différents crawlings dépend du budget crawl attribué au site web.
Qu’est-ce-que le budget crawl ?
Le crawl budget, ou budget crawl, ou encore budget d’indexation correspond au nombre limite de pages que le GoogleBot va explorer en une fois. En pratique, un site au nombre de pages très important (comme un e-commerce par exemple) a un crawl budget plus important qu’un site plus réduit (comme un blog ou un site vitrine). Le GoogleBot crawle les pages de manière très fréquente afin de savoir où positionner le site parmi les résultats de recherche pour une requête donnée. Le crawler est comme un inspecteur qui passe vérifier la teneur, mais aussi les performances techniques du site web. En principe, plus un budget crawl est important et plus le site a des chances d’être correctement référencé si le concepteur met les moyens nécessaires en œuvre. Il est également important de faciliter la navigation des robots en respectant quelques principes, comme :
- mettre en place du maillage interne,
- proposer des titres de différents niveaux,
- réparer les liens cassés,
- etc.
A quoi correspond la phase d’indexation des moteurs de recherche ?
La phase d’indexation est simplement le fait pour un moteur de recherche de positionner les sites web en fonction des résultats observés lors de la phase d’exploration. A l’issue du crawling, le moteur de recherche classifie les sites web selon un algorithme spécifique qui combine, entre autres, les principales informations suivantes :
- pertinence des informations données à une problématique précise,
- originalité du contenu,
- facilité de navigation sur la page (UX),
- performances techniques du site (vitesse de chargement, données structurées, etc.).
Selon l’évaluation attribuée à chacun de ces critères, l’algorithme décide d’un placement du site pour une requête donnée. C’est la stratégie même du référencement naturel. Chaque moteur de recherche dispose d’un algorithme qui lui est propre, développé en interne, afin de classifier les sites selon son propre fonctionnement.
Comment fonctionne l’algorithme Google ?
L’algorithme le plus célèbre est sans surprise celui du moteur de recherche Google. Cependant, il comprend aussi de nombreuses subtilités dont nombre de concepteurs web cherchent à percer les mystères.
Nous savons que l’algorithme prend en compte les différents critères suscités, et qu’il pénalise les tentatives de black hat, qui correspondent à une sorte de “fraude SEO” et tentent de le piéger. L’algorithme est le sujet de réflexion constant du moteur de recherche et évolue deux fois par jour avec une mise à jour importante une à deux fois par an. Par exemple, le filtre Penguin, une version mise à jour de l’algorithme, lancé en 2012, pénalise les sites ayant cherché à acquérir des liens externes (backlinks) de manière frauduleuse : un concepteur achète des liens redirigeant vers son site web à d’autres sites qui n’ont rien à voir avec sa problématique afin d’usurper de l’autorité.
Globalement, Google indique en quoi consistent les nouvelles mises à jour de son algorithme mais ne livre pas les secrets de ses mécanismes, afin de pouvoir garder le contrôle sur le web. Si les règles précises du fonctionnement de l’algorithme étaient dévoilées alors les sites web deviendraient tous irréprochables et le principe même du moteur de recherche s’en trouverait floué.
L’algorithme Google, un cas exemplaire de Machine Learning
L’algorithme Google évolue constamment, et il a été tellement travaillé qu’il est capable de comprendre l’intention de l’utilisateur et également la logique d’une argumentation ou du parcours utilisateur sur une page. En voici un exemple concret : un célèbre logiciel SEO indique à un rédacteur web que le terme “meilleur lait bébé” concentre 720 recherches mensuelles.
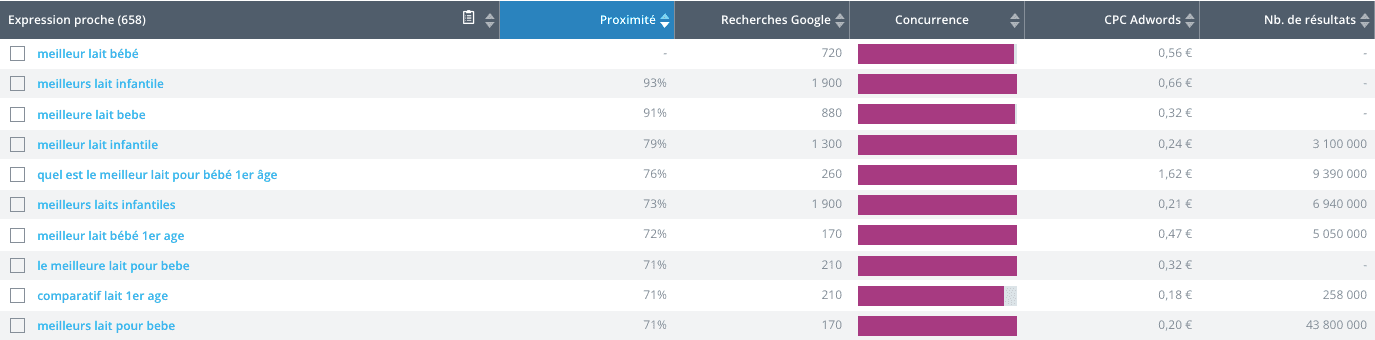
En effet, l’utilisateur à la recherche d’informations saisit cette requête dans la barre de recherches. En revanche, le rédacteur, qui rédige un article sur cette requête, ne peut pas saisir ces termes exacts, étant donné que ce n’est pas correct linguistiquement parlant. La page nommée “Quel est le meilleur lait pour bébé ?” tombera néanmoins dans les résultats de recherche de la requête “meilleur lait bébé” puisque Google détecte l’intention de la recherche et l’associe à la thématique de la page. Il peut même associer des contenus dont les nominations divergent complètement des termes de recherche s’il détecte une certaine pertinence entre l’information donnée et la requête saisie. Comme en témoigne l’exemple ci-dessous, le premier résultat de recherche pour la requête “meilleur lait bébé” est une page dont le titre est “Meilleur lait 1er âge en 2021 (bébé de 0 à 6 mois)”.
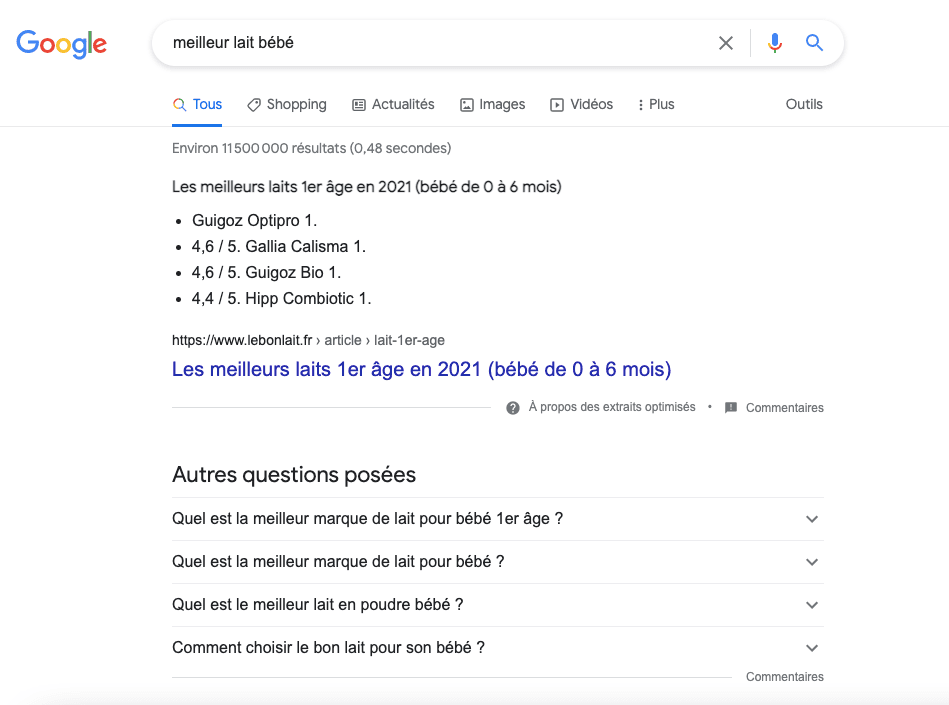
L’algorithme Google est ainsi une intelligence artificielle s’appuyant sur le machine learning, capable de faire ses propres choix et de détecter les parcours linguistiques et logiques entrepris par les utilisateurs.
Les pénalisations et actions manuelles de Google
L’algorithme n’est pas le seul agent opérationnel dans le jeu de l’indexation des sites web. Il existe également des agents Google qui examinent un site web après une détection automatisée ou bien après une dénonciation de pratiques contraires aux principes de Google. Ces actions ne sont pas automatisées mais dépendent bien du passage d’agents humains, c’est pourquoi on les appelle des actions manuelles. Elles sont bien souvent à l’origine d’une baisse de trafic et peuvent être repérées via la Google Search Console. A la suite d’une pénalité manuelle, il est possible de corriger les erreurs et de demander un nouvel examen afin de lever cette dernière.
Comment faire en sorte que l'algorithme favorise mon référencement naturel ?
Pour que le moteur de recherche positionne un site web en haut de ses résultats de recherche, on met en application les principes du référencement naturel ou SEO (Search Engine Optimization). Le SEO est une science technique qui évalue les différents critères de référencement optimal d’un site et met en place des modifications afin de valoriser ce dernier aux yeux de l’algorithme. Pour être clair, le SEO ne vise pas à duper le moteur de recherche, mais bien à satisfaire ses demandes afin d’optimiser les qualités d’un site. Ainsi, concrètement, le but du SEO est de rendre un site web pertinent, rempli d’informations et de contenu original et de l’adapter entièrement aux besoins des utilisateurs du point de vue navigationnel.
La rédaction web
La rédaction web est un pan très important du SEO, visant à optimiser les contenus éditoriaux et rédactionnels d’un site web afin de satisfaire les moteurs de recherche. Si auparavant, le SEO consistait principalement à placer de nombreux mots-clés en rapport avec une requête au sein d’un texte, cette activité a évolué, comme l’algorithme Google.
La rédaction web vise dorénavant :
- la qualité rédactionnelle (phrases courtes et concises)
- l’originalité (son unicité, en interdisant le copier/coller)
- la richesse informationnelle (maillage interne et liens externes)
- la hiérarchie structurelle (l’implémentation de titres et sous-titres)
d’un contenu.
L’UX Design
L’UX d’une page d’un site web concerne son ergonomie navigationelle : est-il aisé de naviguer sur la page et d’y trouver les informations recherchées ? Le SEO comprend ainsi tout un pan dédié à l’esthétisme et au confort de lecture de la page. On adopte plusieurs techniques distinctes pour optimiser l’UX, mais parmi elles notamment :
- l’insertion de médias (illustrations, vidéos, infographies),
- la mise à disposition de boutons CTA (call to action, qui desservent une action mise en avant sur le site “en savoir plus”, “nous contacter”...),
- le travail de la colorimétrie pour mettre en valeur certains points,
- la disposition des contenus à un endroit précis de la page.
L’optimisation du temps de chargement
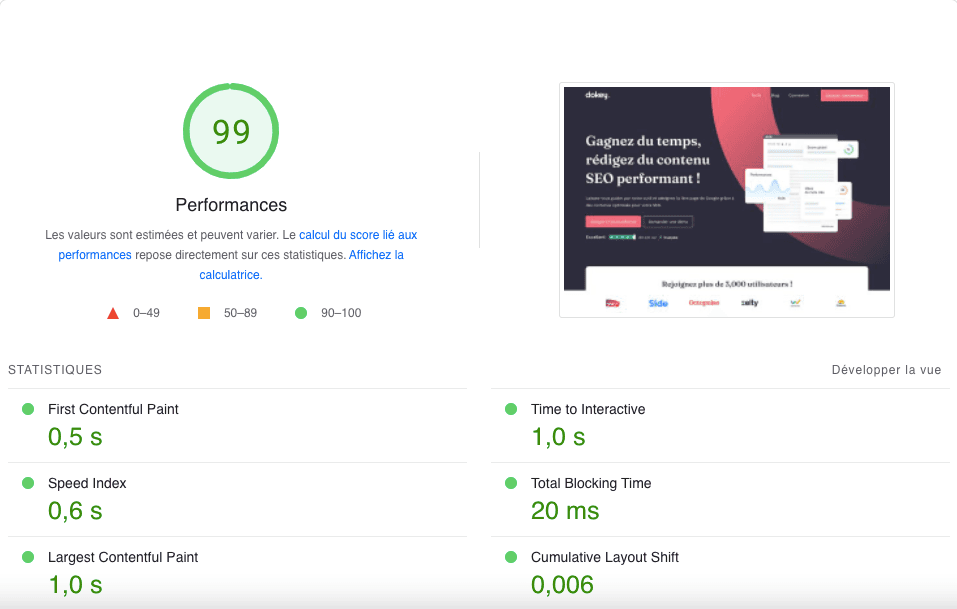
200 millisecondes, soit 2 secondes : c’est le temps de chargement maximum alloué à une page web. Le serveur, les contraintes techniques du site, mais aussi son contenu, déterminent le temps de chargement d’une page. Il faut sans cesse vérifier le temps de latence des pages d’un site afin de réduire les médias ou si possible refactoriser les pages trop lourdes à charger. Mieux vaut se passer d’une page de contenu que de la voir ralentir les performances du site.
L'autorité
Enfin, l’autorité d’un site constitue également l’objectif de nombreux travailleurs du web. Le but : montrer patte blanche à Google et faire valoir l’expertise et le sérieux d’un site. La méthode : acquérir des backlinks auprès d’autres sites, développer son expertise auprès d’autres médias (livres, télévision, radio, podcasts…)...
