The guide to Technical SEO
On-Page SEO, Off-Page SEO, local SEO… so many subdivisions of SEO whose subtleties are sometimes difficult to integrate. What is Technical SEO? What are the technical tools to improve its natural referencing? How to understand technical SEO today?
Table of contents
- Technical SEO: what is it?
- The different methods of technical SEO
- The creation of a sitemap
- The provision of a robots.txt file
- Setting up the Ariadne's thread
- A mobile-friendly interface
- A reasonable loading time
- The canonicalization of URLs
- Image tagging
- Using the Google Search Console
- Pay special attention to the depth of the pages
- The introduction of the hreflang tag for multilingual sites
- Regular technical audits
Technical SEO: what is it?
Technical SEO differs from what could be called “editorial SEO”. Where so-called “editorial” SEO focuses more on aspects specific to the content and in particular the text, technical SEO focuses on the more practical aspects of putting a page online.
A distinction that tends to disappear
A few years ago, when SEO was mainly related to web writing, it was believed that there was indeed “classic” SEO on the one hand and technical SEO on the other. Indeed, at the time, SEO writing was rather considered as a discipline adapted to so-called “literary” profiles and it did not involve the implementation of technical devices favoring SEO. Webmasters or developers took care of it. It must be said that the technical implementations of the time were rather derisory and that SEO writing was almost self-sufficient (if we want to exaggerate). Over the years, natural referencing has improved and now web writing is no longer enough to obtain an interesting positioning, or even to index a web page. SEO has evolved and become more technical over time.
Technical SEO, on-page SEO and off-page SEO
Technical SEO is therefore traditionally distinguished from On-Page SEO and Off-Page SEO. That is to say that technical SEO does not concern:
- the editorial content of the page (i.e. On-Page SEO)
- the authority of the site (i.e. off-page).
Technical SEO thus concerns the technical aspects of the site that will allow robots to crawl the pages, then index them and finally assign them a position among the results of the SERP. Also, the techniques and methods of technical SEO are very similar to those that are recommended to promote indexing.
The different methods of technical SEO
The techniques and methodologies presented are complementary: it is not enough to apply one or some of them to fulfill the prerequisites of technical SEO.
The creation of a sitemap
Any website worthy of the name must absolutely have a sitemap. The sitemap is a site map that will allow crawlers to find their way around the various pages and navigate the site in order to index it. The sitemap is also a document more accessible to robots than to humans since it lists the URLs one by one and not according to a real map as one might expect. It is possible to generate the sitemap directly from online tools so that it is well understood by crawlers.
The provision of a robots.txt file
The robots.txt is entirely intended for spiders (the crawler robots). It lets them know which pages should be crawled and which should not. This makes it possible not to highlight pages which do not have to be and which could therefore harm the indexing of the site in general (basket pages for an e-commerce, institutional pages for an informative site, etc.).
Setting up the Ariadne's thread
The history of the Ariadne's thread goes back to Greek mythology, and more precisely to the episode of the Iliad narrating the adventures of Ariadne and Theseus. Trapped in a labyrinth where a dangerous and cruel minotaur is locked up, Thésée promises Ariane to marry him if she gives me her thread which will allow him to find the exit. After killing the minotaur, Theseus abandons Ariadne on the island of Naxos. It's not very nice, but the essential is there: the thread allows Theseus to come out of the labyrinth and thus find his way. It is also the usefulness attributed to it in SEO and the reason why it was named so. The Ariadne's thread allows the robots to locate themselves on the site and to understand which are the related pages between them. If they already have the robots file and the sitemap, it is nevertheless agreed that each page must include the famous breadcrumb trail. Finally, note that it is also much more practical for the user!
A mobile-friendly interface
The website interface must be fully responsive and adapt to all mobiles, whatever the page and whatever the device. From now on, about ⅔ of users browse the web using a mobile, against only ⅓ via Desktop. This is why, since 2016, Google has implemented a Mobile-First index which indexes websites according to the rendering and response time applicable to the mobile version and no longer to the Desktop version. Thus, it is absolutely imperative to work on a responsive and mobile-friendly of the website (and each of its pages)!
A reasonable loading time
3 seconds…this is the maximum loading time for a user and for indexing robots! Make sure that your site (and each of its pages for that matter) offers a loading speed that satisfies the user and the robots, i.e. a loading speed of less than 3 seconds. Our tip: test the latter via LightHouse, which uses servers all over the world and offers an average of these, where other more traditional solutions use a nearby server which, inevitably, reduces the loading time felt.
Optimize loading time
Half of the users of a website abandon their navigation on the latter if the loading time is greater than or equivalent to 3 seconds.
The canonicalization of URLs
A barbaric word for a technique…completely logical and relevant! Telling the robots which are the canonical URLs allows, for several similar or even identical pages, to indicate to the robots that there is a similarity without however being penalized because of Duplicate Content. Let's take a concrete example: I have an e-commerce that offers sporting goods. For SEO purposes, I created a level 1 section dedicated to boxing gloves. But, for the sake of logic, this page dedicated to boxing gloves is also in the level 2 category “Boxing”. A robot passing by could penalize my site because of this duplicate. Unless I told him beforehand that the 2 similar URLs, one prevailed over the other and that as such, I do not deserve to be penalized since I declared the duplication to the robots of upstream indexing. Thus, I declare as canonical the URL that I want to highlight the most (in this case the URL located in the “Boxing gloves” category). From there, robots noticing a striking resemblance will not be able to penalize me since I have warned. They will only index the page corresponding to the canonical URL, but not the others.
Image tagging
A robot crawler does not have the same skills as a human to appreciate an image. This is why it is important to mention to him what the image contains and what it represents. Hence the existence of the Alt tag which allows you to submit a nominal description for each image. The latter being necessarily directly related to the problem of the page and therefore with its keywords, this also makes it possible to reinforce the density of the latter and therefore to optimize the referencing of the page. In other words: strictly prohibit yourself from uploading an image without assigning it an Alt tag.
Our advice: propose an optimized Alt tag which will allow you to gain points in terms of positioning and also think that the latter can sometimes replace the image in the event of impossibility of display.
Using the Google Search Console
The Search Console is one of the tools offered by Google to assess the performance of a website. In particular, it allows you to notify any exploration problems that may occur on the site, such as structured data problems, 404 errors, non-responsive pages (not adapted to mobiles) or even Core Web Vitals. Google Search Console is a valuable tool that alerts the webmaster in the event of a problem and informs him about the regularity of the crawls. This is the easiest and most reliable method of obtaining data relating to the indexing of your website.
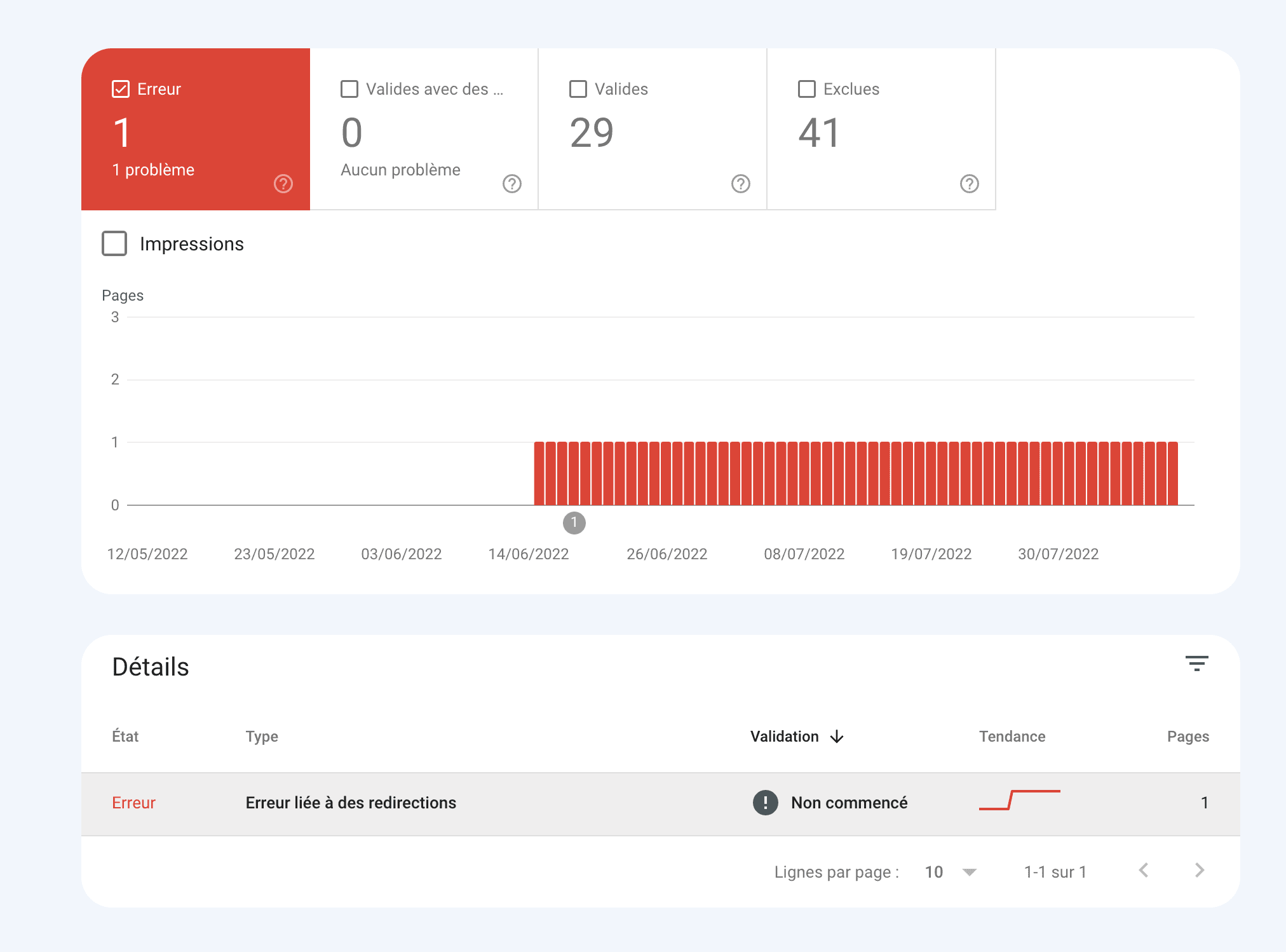
Example of an error on the Google Search Console
Pay special attention to the depth of the pages
Did you know? The more a page has a high level of depth, the less likely it is to be indexed by crawlers. Why ? Because from home, the access path is all the more difficult as the page is far away. To calculate the depth of a page, simply estimate the number of clicks from home via the most direct path. It is for this reason in particular that technical SEO professionals recommend designing tree structures with a maximum of 2 or 3 levels. Otherwise, the most distant pages are less accessible and the site map is not correctly understood by the robots.
The introduction of the hreflang tag for multilingual sites
Are you developing an international strategy? Do you offer your site in .uk and .com (British English and American English)? Is your site translated into one or more different languages? Then you must install the hreflang tag which allows Google to understand the international intention of a website. domain name extensions, when they are multiplied (the same page in .fr, .co, .uk, .de, .es, etc.) had the gift of making the task difficult for robots and therefore of penalizing the website positioning. Now, the hreflang tag informs Google of the site's multilingual strategy and in particular avoids problems with duplicate content between several languages.
Regular technical audits
Finally, to control the technical SEO of a site as well as possible and to realize an error, the best method consists in carrying out regular technical audits in order to control the health of the website. Some solutions even allow you to schedule audits, so you don't have to think about it. In general, a monthly audit is more than enough, unless you make multiple, daily changes to the site. SEO audits often make it possible to also control different aspects of on-site SEO and off-site SEO: it is therefore the best existing method to date to optimize all aspects of technical SEO (in addition to the use of the Google Search Console).
